Representing the University at UCISA Women in Tech 2026: My takeaways and reflections
I was pleased to have a talk accepted at the annual UCISA Women in Tech (WiT) conference. I went to Newcastle for a day of talks, workshops and networking. I left with a better understanding of the WiT community , and a reinforced appreciation of the need for inclusivity in Higher Education.
UCISA is an industry body supporting digital professionals working in the education sector. I have been actively involved in UCISA since 2022 when I helped set up the UCISA UX Group and became co-chair of this UK-wide community of practice. I’ve organised many UCISA UX events but had not attended one of UCISA’s flagship annual conferences, the Women in Tech event, until this year. My presentation about our project on staff profiles resonated with attendees, I learned a lot about diversity and representation in the sector from attending the other talks and I enjoyed connecting with other Higher Education professionals over shared inclusivity challenges. Here, I reflect on my highlights from an interesting day.
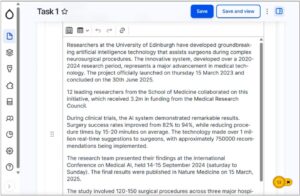
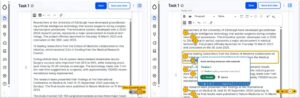
Sharing our staff profiles work piqued interest from other universities
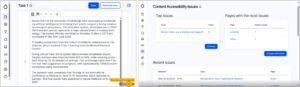
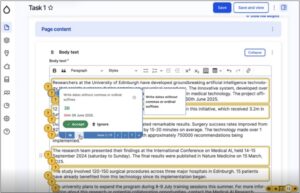
As well as the clear focus on inclusivity, one of the themes of this year’s WiT was real-world applications and problem-solving. I felt our staff profiles project spoke to this theme, so I submitted a talk to share what we learned from research and the steps we have taken towards finding a new profiles solution.
My session was well received – perhaps unsurprisingly, colleagues from other institutions shared the same concerns and challenges in designing a profile solution that showcases staff in the best light, keeps them findable in searches, and yet remains easy for staff to update. I valued the chance to make new contacts, exchange ideas, and learn about other institutions’ diverse approaches to the ‘profiles problem’. I resolved to stay in touch as we take steps towards implementing a profiles solution at the University, recognising just how universal this need is across the Higher Education sector, and seeing an opportunity for meaningful collaboration.
Read more about the staff profiles project in the blog post series:
Collected blog posts about staff profiles project
Results of a 2025 WiT survey revealed risks and opportunities
One of the core activities of the UCISA WiT committee is to regularly collect data to understand diversity within IT departments across the FE/HE sector. At the conference, WiT committee co-chairs Christi Hopkinson and Katie Wilde shared a preview of the results of the 2025 survey, completed by more than 200 respondents from 66 institutions, with 74.5% of the respondents identifying as female. Several findings stood out from the preliminary report in terms of risks and opportunities.
There’s a risk of retention due to barriers to progression
Responses to a question about progression routes revealed significant proportions of respondents had started in IT in the following areas:
- First/Second Line Support
- Application Support
- Business Analysis
- Project Management
- Web Development
Responses to a follow-up question about the roles respondents were currently working in showed continued representation in these areas, which indicated a degree of stasis when it came to progression in the sector. Areas where women were underrepresented included:
- Infrastructure
- Security
- Enterprise Architecture
- Senior Management.
The survey results showed a third of respondents had considered leaving their institutions or the sector, citing pay, workload and progression as popular reasons motivating them to think about moving on. Common blockers to progression included:
- Lack of available higher-grade roles
- Promotion structures tied only to management, not technical excellence
- Career pathways not transparent
- Women having to ‘prove more’ to progress
There’s potential to be gained by investing in non-technical skills
Most respondents cited the following skills as important for the roles they were currently in as well as for progression:
- Problem solving
- Communication
- Analytical skills
- Customer service
- Business analysis
- Strategic thinking
This spread of skills reinforced the value of focusing training and development on non-technical abilities to complement technical skills, and to ensure expertise was appropriately directed to deliver on broader institutional goals.
There’s room to improve on diversity, inclusion and discrimination
Responses to questions about inclusion and belonging revealed positives and negatives about the workplace respondents were part of.
On the positive side:
- 79% felt valued as part of a team
- 67% felt they were treated fairly and equitably
On the less-positive side:
- Only 34% felt the leadership reflected diversity in the workforce
- 41% felt there were opportunities for careers advancement
- 46% felt their organisation supported under-represented groups
- 47% were satisfied with their organisation’s diversity initiatives
The spread of these numbers provided a clear steer of areas to focus on to achieve less exclusive, and better-balanced IT workplace.
Achieving inclusivity starts with individuals and requires thinking beyond statistics
The survey data gave a snapshot of the current state of inclusivity in the sector, however, anecdotes from individual presenters painted a more vivid picture of what inclusivity could look like. The WiT programme included several women sharing stories of their induction into tech and reflecting on their individual progression routes. It was refreshing to see the diversity of pathways they had taken and interesting to hear about what they had learned along the way, and their tips for success.
Monica Jones, Chief Data Officer at the University of Leeds acknowledged that career progression paths rarely run smoothly, and advised setting personal goals and milestones to work towards, to be best-prepared for promotion opportunities when these came up. Julia Lloyd, College Manager – Business and Law, at the University of the West of England, emphasised the benefits of ‘quiet leadership’ and shared tips to create space for different voices – such as thoughtful structuring of meetings, design of communication channels and rewarding contributions over confidence. A joint talk ‘The Not-So IT Crowd’ from Catriona Blair, Joanna Addison and Sasha Titus from the University of Kent, and a session by Amber Mothersille from the University of Northampton emphasised the value of non-technical skills in technical roles – recognising the need for empathy, trust-building and adaptability to strengthen teams and build excellent digital services.
Breaking barriers requires breaking old biases and habits
A final takeaway from attending the WiT event was a call-to-action to question the way we work – specifically to foster inclusivity by making room for new ways of thinking and for fresh perspectives.
In an interactive exercise led by Katie Wilde, we considered five roles necessary for the operation of successful teams (the Navigator, the Connector, the Builder, the Challenger). In a period of honest reflection, we shared the roles we naturally adopted in team settings, and the roles we tended to overlook or disregard. Going through this exercise was a good leveller as well as a reminder to make room for diversity in everyday team settings instead of relying on familiarity.
The day closed with a thought-provoking talk on male fragility, delivered by Jake Dovey, a UCISA mentor. Drawing on personal anecdotes experienced through his involvement with UCISA, Jake’s talk described instances where men had overreacted defensively to being challenged and where women had inadvertently softened situations to avoid potential conflict and ‘keep the peace’. Jake challenged the women in the room to recognise these instances going forward, and prompted a call-to-action for all to recognise these harmful patterns and call them out to collectively help break the disruptive cycle.
Final thoughts – WiT26 was less about women and more about inclusivity
WiT26 delivered a packed programme which encouraged me to think outside my work in UX and more broadly about the joint responsibilities we all have in creating and fostering an inclusive work environment. I came away with recommendations of books to read and concepts to learn more about, and a heightened awareness of embedding inclusive practices in my day-to-day work and activities. I am keen to see the full results of the WiT 2025 survey and to remain part of the WiT community going forward.